Q Learning
Training Loop
- Compute Action and use epsilon greedy
- If
np.random.random()<epsilon, Choose a random action
action = torch.tensor(random.randint(0, self.num_actions - 1)) - Else choose from critic network
action = self.critic(observation).argmax(dim=1)
-
Step environment
-
Add data to replay buffer
replay_buffer.insert(...) -
Sample from replay buffer
batch = replay_buffer.sample(config["batch_size"]) -
Train agent, we update the target critic network only every fixed timestep and the critic network every timestep
- If
step % self.target_update_period == 0:
Update target critic network
self.target_critic.load_state_dict(self.critic.state_dict()) - Update critic network
self.update_critic(obs, action, reward, next_obs, done)
Update Critic
- Compute all options of q_values
next_qa_values = self.target_critic(next_obs) - Choose q_values: If using Double Q,
# Use critic network to update actions
next_actions = self.critic(next_obs).argmax(dim=1)
# Choose the Q values based on actions
next_q_values = next_qa_values.gather(1, next_actions.unsqueeze(-1)).squeeze(-1)
- Else just use the max Q values
next_q_values = next_qa_values.max(dim=1).values
-
Compute target_values
target_values = reward+self.discount*next_q_values*(~done) -
Get q_values from critic network
q_values = self.critic(obs).gather(1, action.unsqueeze(-1)).squeeze(-1) -
Compute loss function
loss = self.critic_loss(q_values, target_values) -
Update critic network
self.critic_optimizer.zero_grad()
# Gradient clipping
loss.backward()
self.critic_optimizer.step()
Experiments to Run
# Cartpole
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/cartpole.yaml
# Lunar_Lander
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/lunarlander.yaml --seed 1
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/lunarlander.yaml --seed 2
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/lunarlander.yaml --seed 3
# double q
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/lunarlander_doubleq.yaml --seed 1
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/lunarlander_doubleq.yaml --seed 2
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/lunarlander_doubleq.yaml --seed 3
# Pacman
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/mspacman.yaml
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/mspacman_lr_3e-4.yaml
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/mspacman_lr_5e-4.yaml
python cs285/scripts/run_hw3_dqn.py -cfg experiments/dqn/mspacman_lr_5e-5.yaml
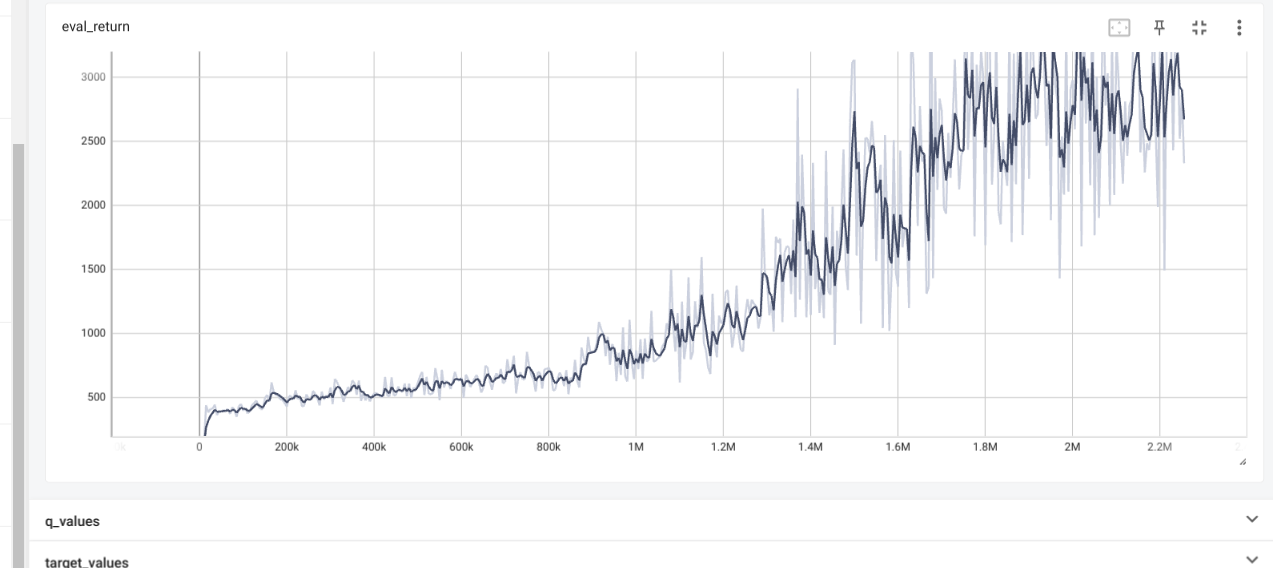
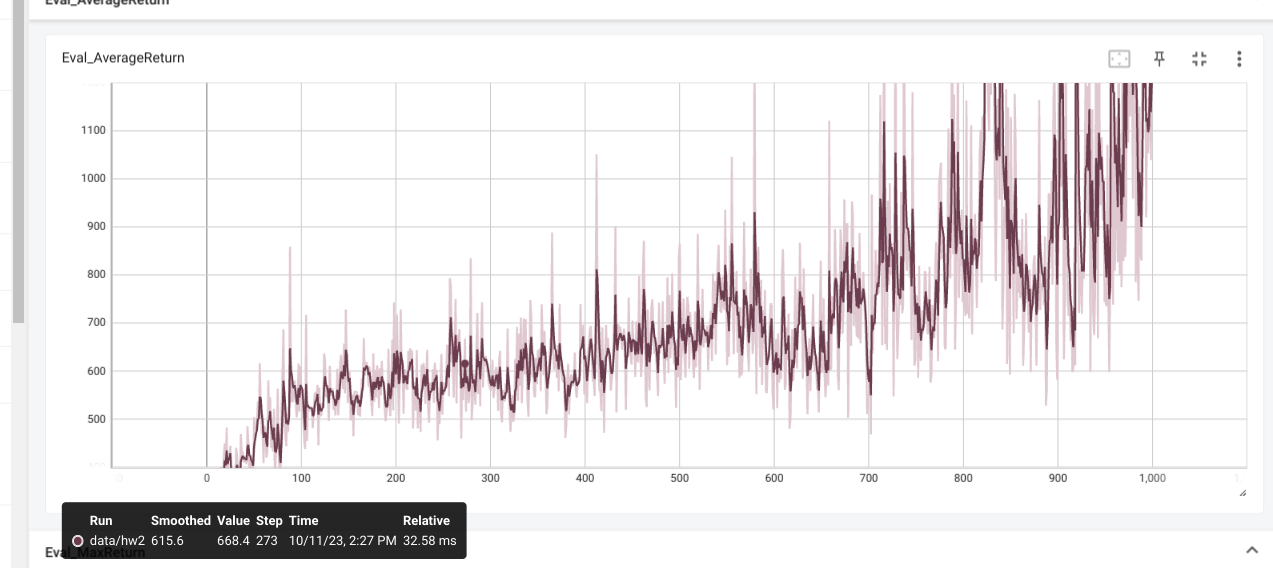
Results
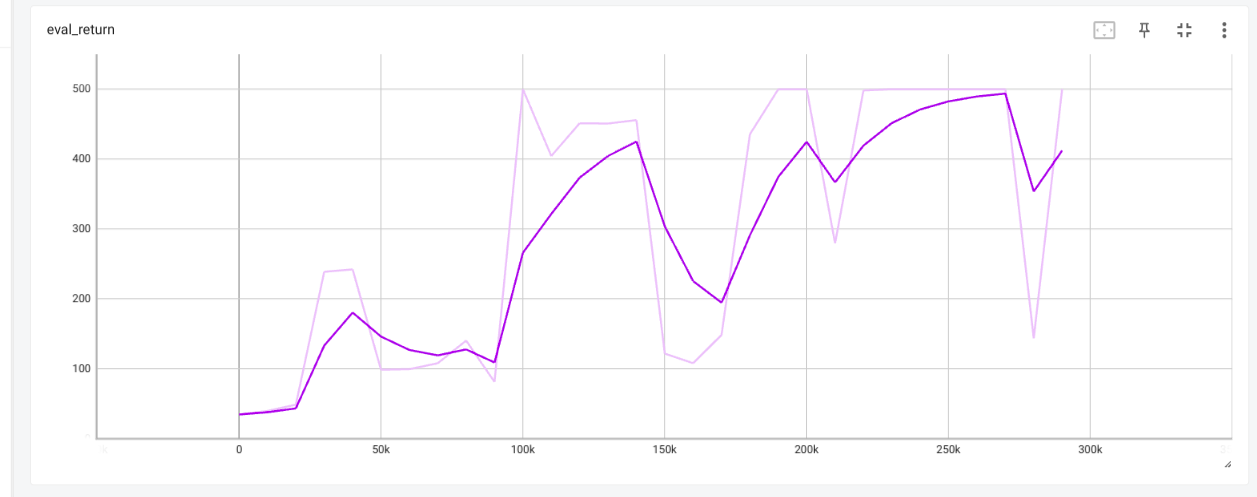
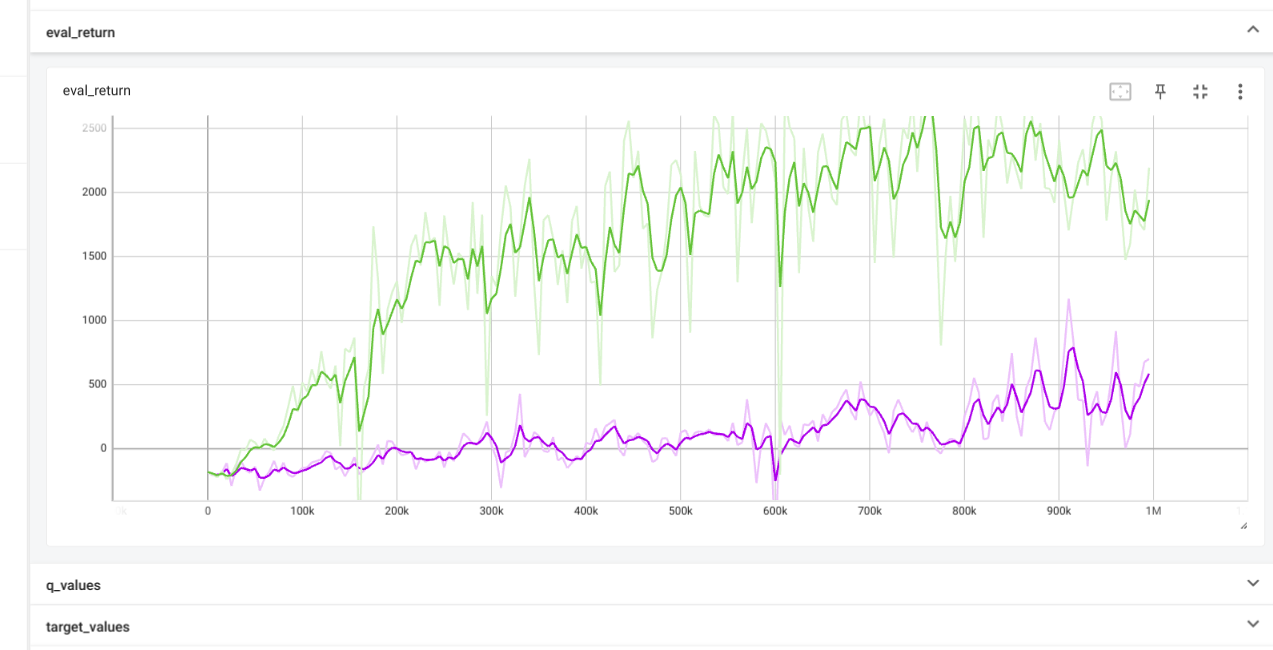
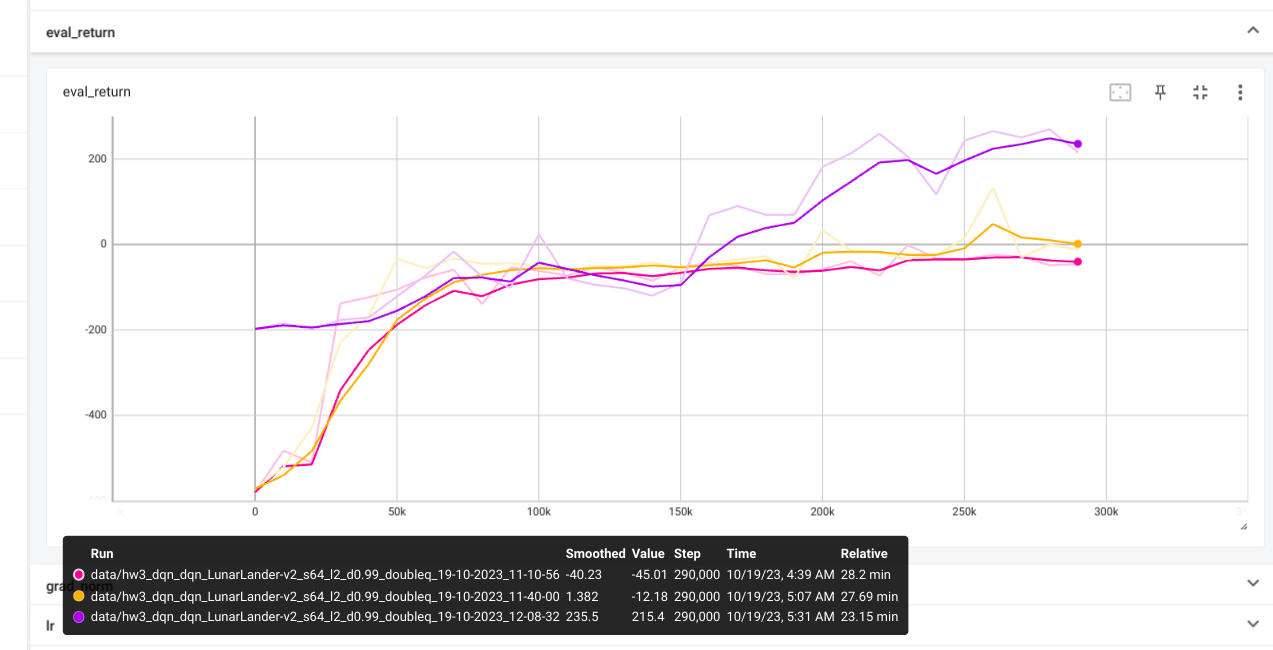
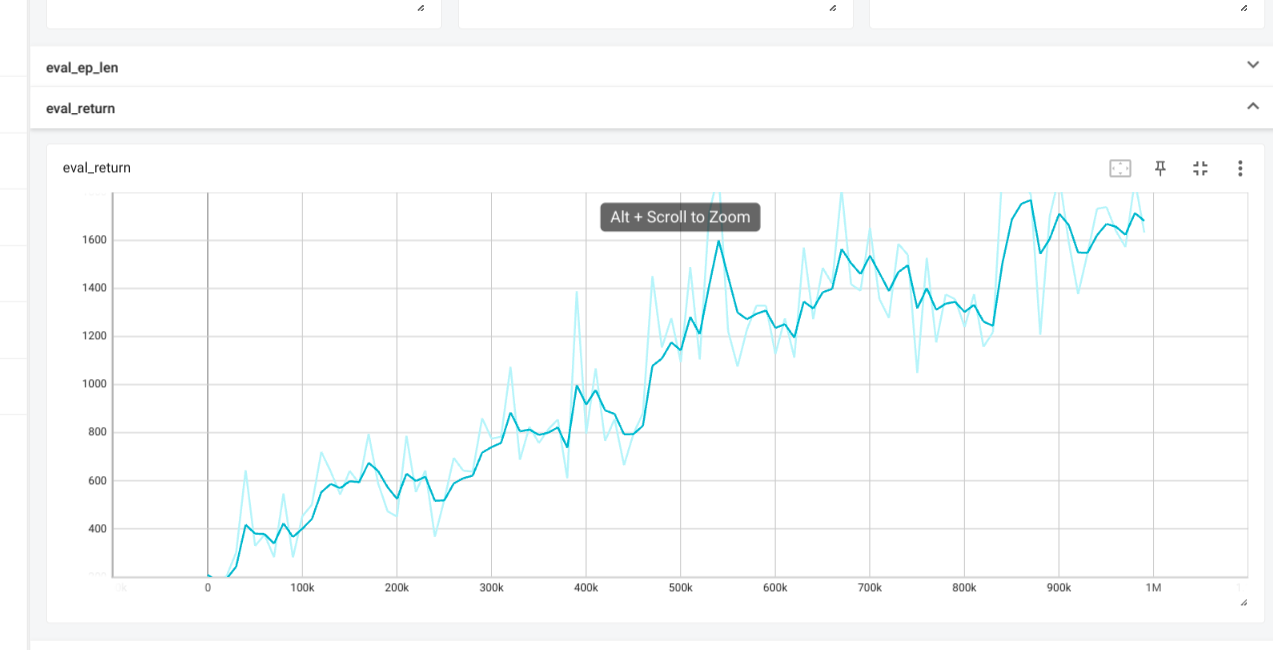
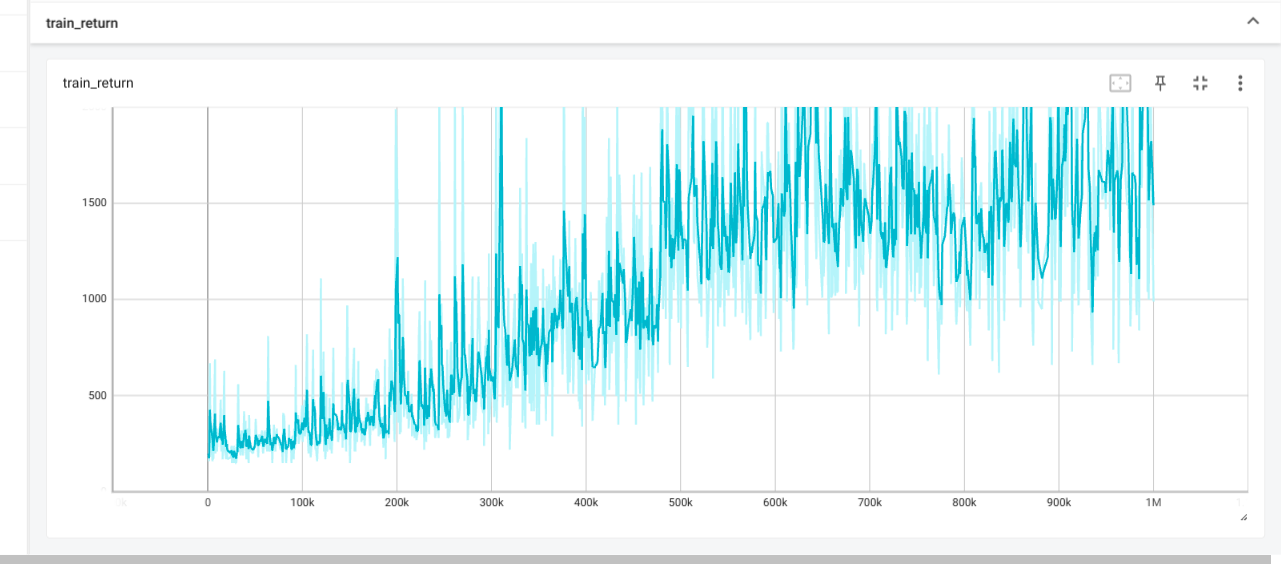
If learning rate of CartPole is too high then the predicted q values and
critic error are both very high, leaing to overestimation.
SAC
Training Loop
- Compute Action
- Random sampling(at first)
action = env.action_space.sample()
- Step environment
- Add data to replay buffer
- Sample a batch from replay buffer
- Train agent by updating actor and critic
Normally we use 1 critic.In SAC we use 2 critics and on every fixed timestep we soft update the target critic target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau) , in math soft updates
Entropy
Objective function for policy with entropy bonus.
In code
-action_distribution.log_prob(action_distribution.rsample()).mean()
Update Critic
- Get Actor Distribution
- Sample from actor
- Get q_values
- Double-Q(switch to reduce variance)
- Clipped double-Q:
- Compute Entropy(if used)
is a binary value (0 or 1)
- Compute the target Q-value
REINFORCE
Actor with REINFORCE
REPARAMETRIZE
Actor with REPARAMETRIZE
Objective function for policy with entropy bonus.
In code: loss -= self.temperature * entropy
Experiments to Run
# SAC
# HalfCheetah
python cs285/scripts/run_hw3_sac.py -cfg experiments/sac/halfcheetah_reinforce1.yaml
python cs285/scripts/run_hw3_sac.py -cfg experiments/sac/halfcheetah_reinforce10.yaml
python cs285/scripts/run_hw3_sac.py -cfg experiments/sac/halfcheetah_reparametrize.yaml
# Hopper
python cs285/scripts/run_hw3_sac.py -cfg experiments/sac/hopper.yaml
python cs285/scripts/run_hw3_sac.py -cfg experiments/sac/hopper_clipq.yaml
python cs285/scripts/run_hw3_sac.py -cfg experiments/sac/hopper_doubleq.yaml
# Humanoid
python cs285/scripts/run_hw3_sac.py -cfg experiments/sac/humanoid.yaml
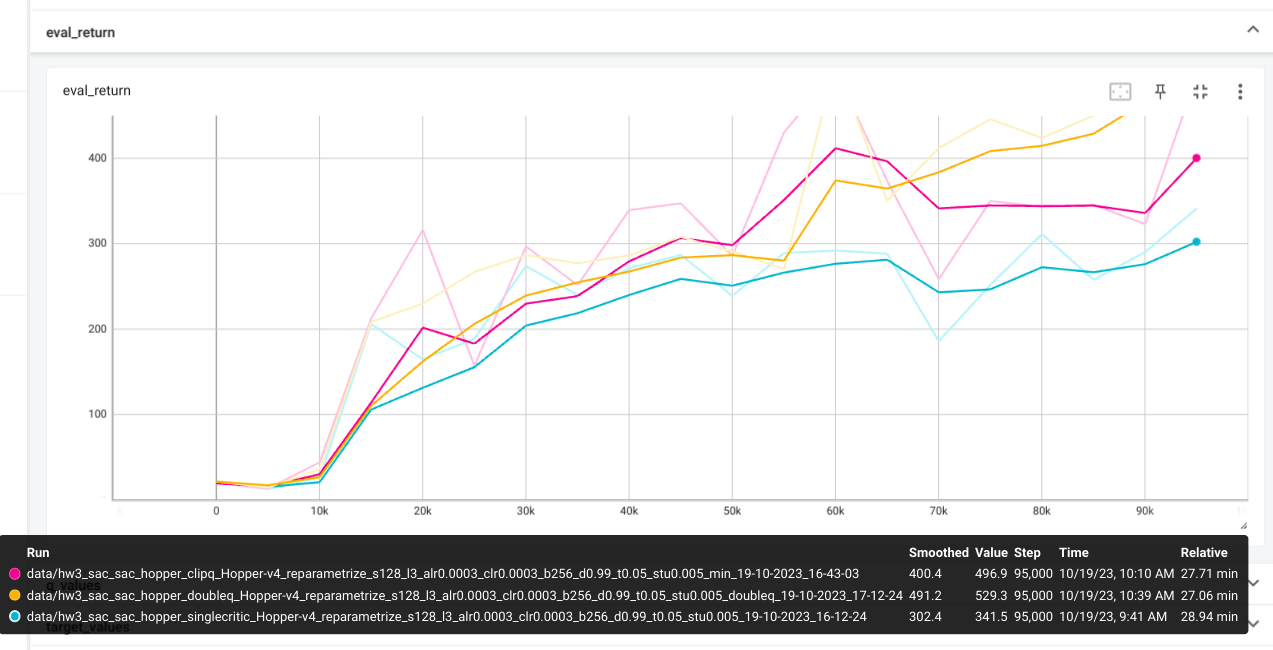
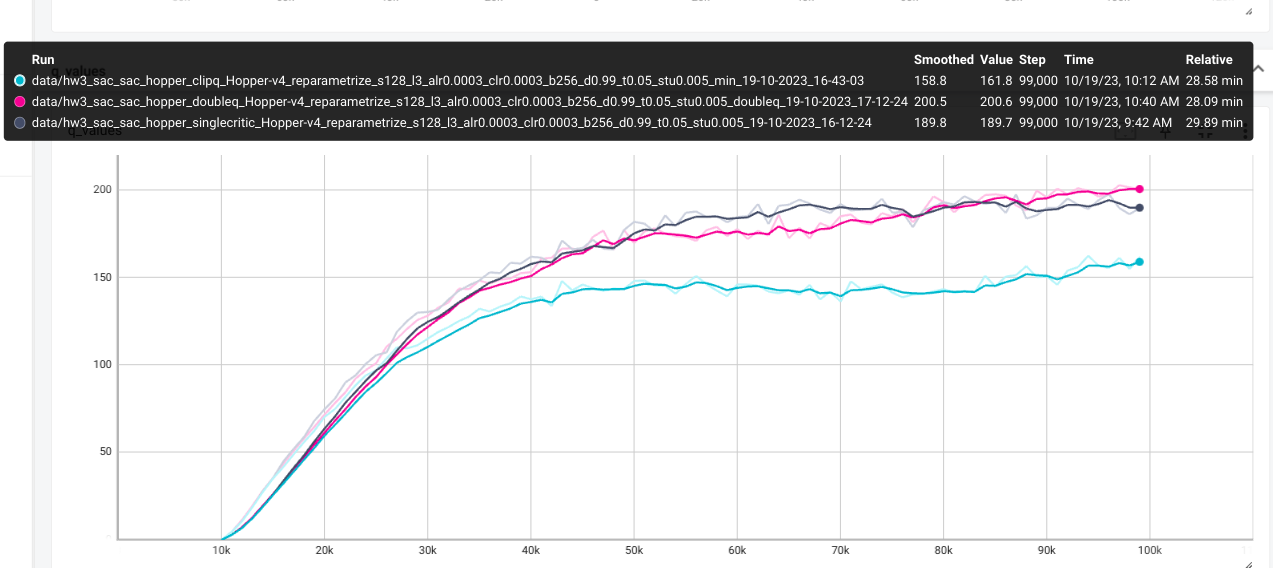
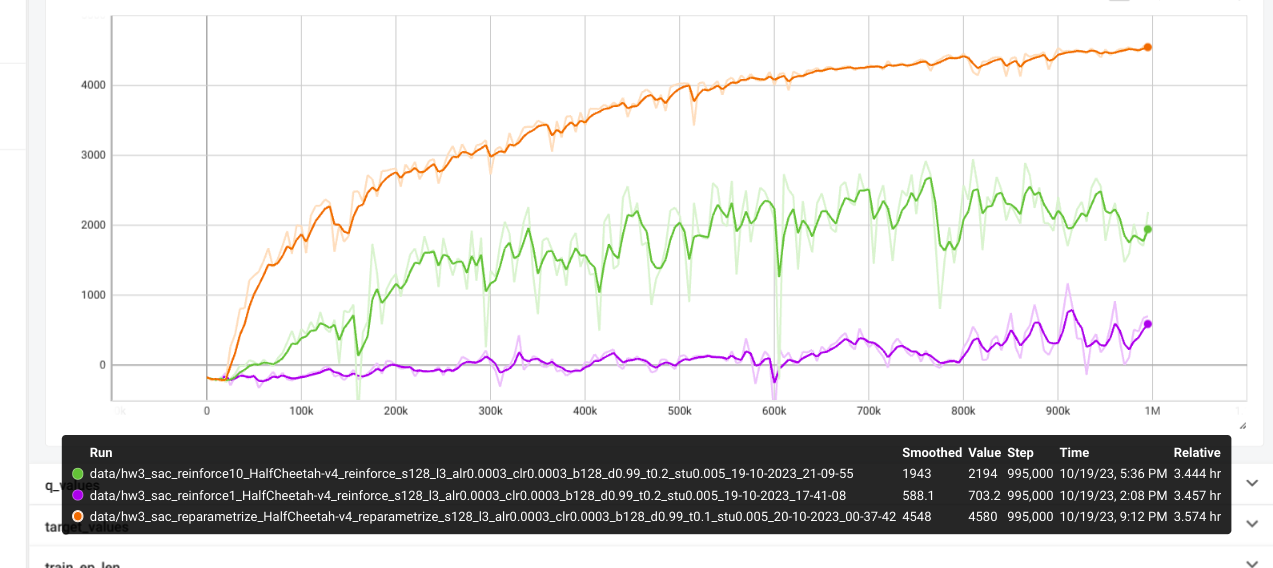
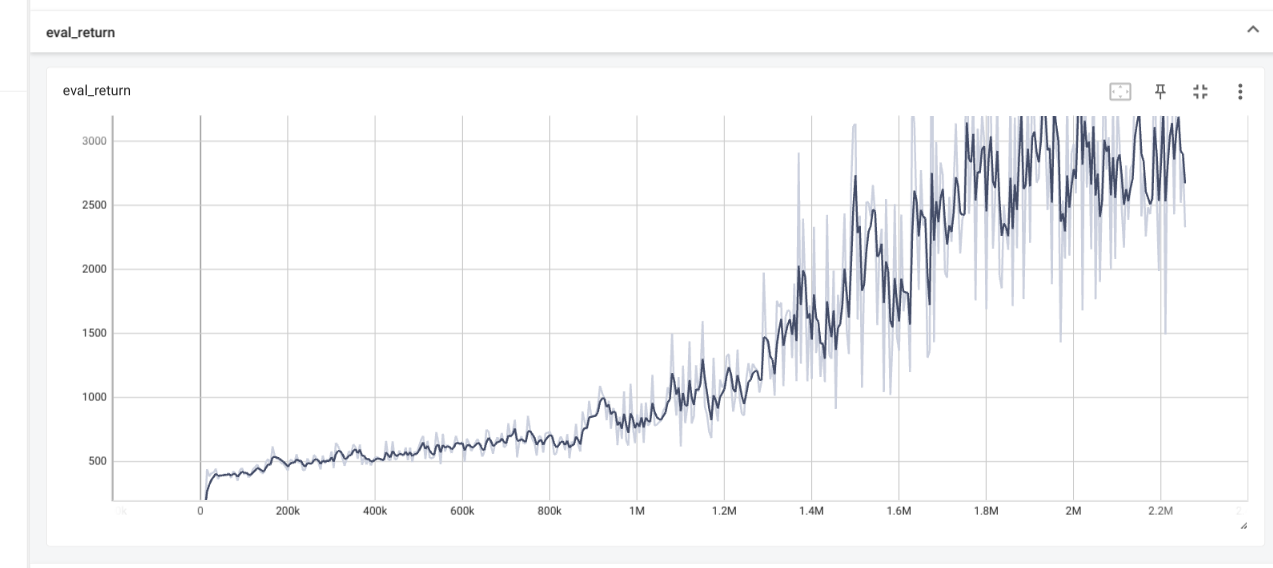
Results
The Q_values tend to be more stable with clipq. Singleq overestimates
Q_values. Thus singleq tend todrop in performances.