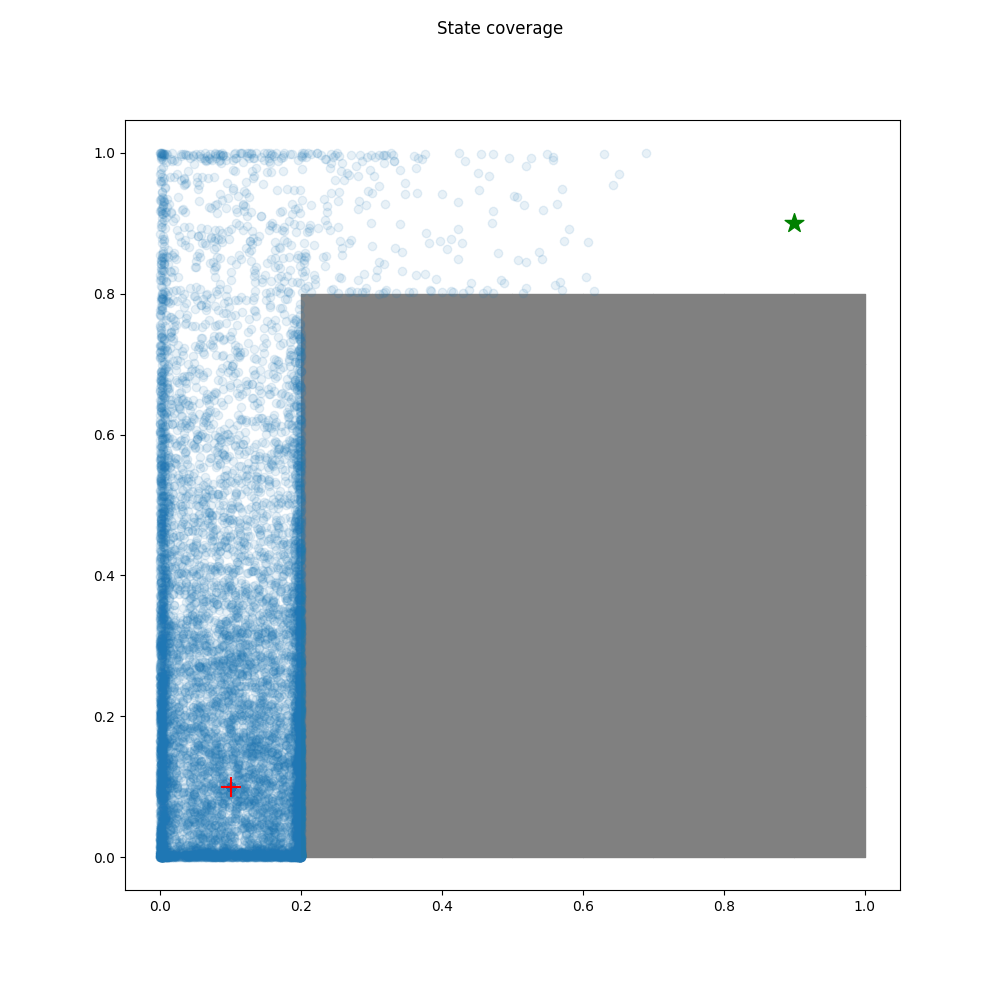
Exploration
Note: All Yaml files are in the git repo: https://github.com/jimchen2/cs285-reinforcement-learning
random Agent
python cs285/scripts/run_hw5_explore.py \
-cfg experiments/exploration/pointmass_easy_random.yaml \
--dataset_dir datasets/ --log_interval 1000
python cs285/scripts/run_hw5_explore.py \
-cfg experiments/exploration/pointmass_medium_random.yaml \
--dataset_dir datasets/ --log_interval 1000
python cs285/scripts/run_hw5_explore.py \
-cfg experiments/exploration/pointmass_hard_random.yaml \
--dataset_dir datasets/ --log_interval 1000
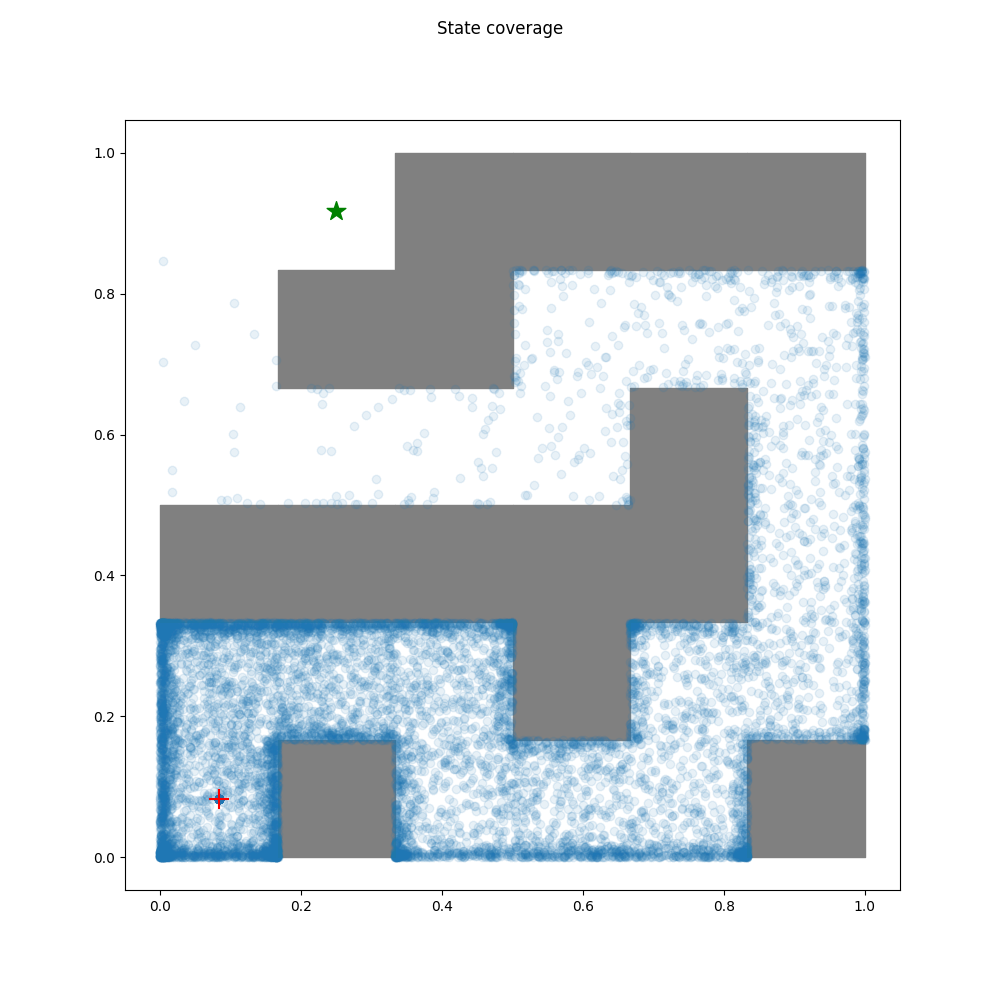
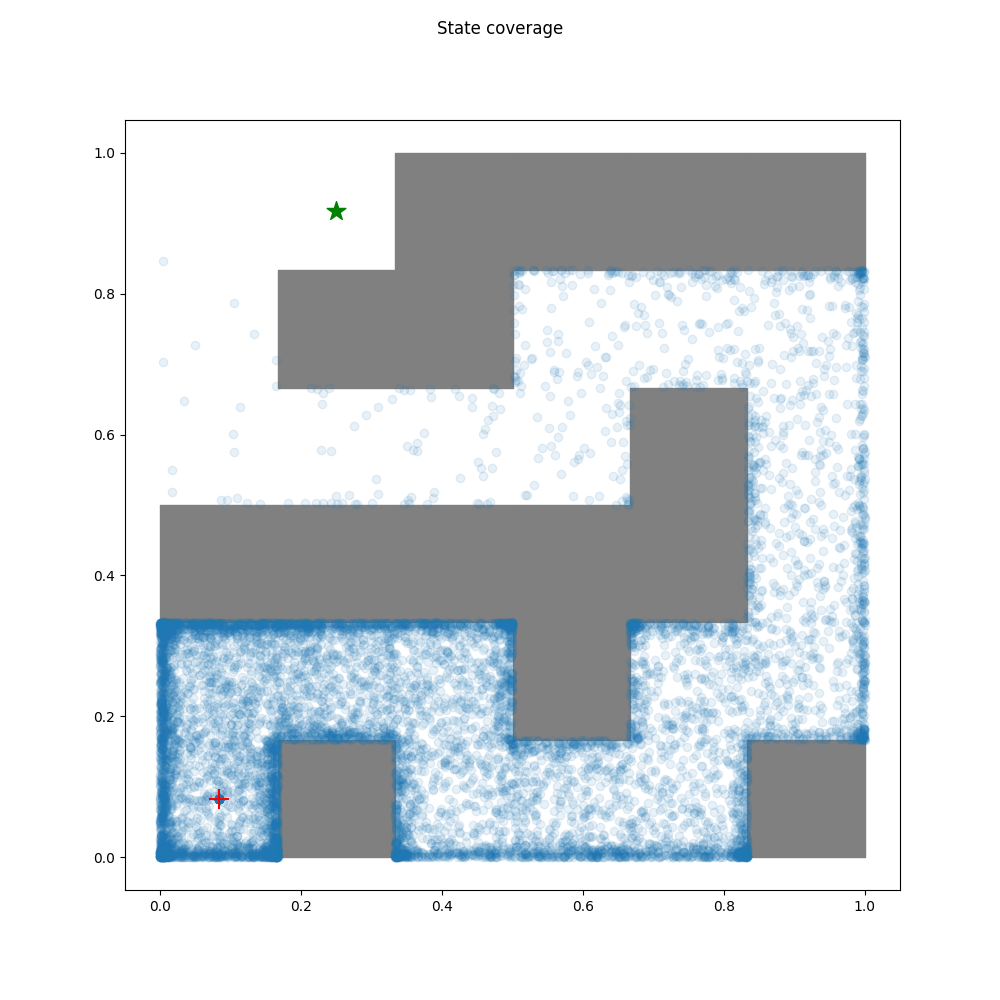
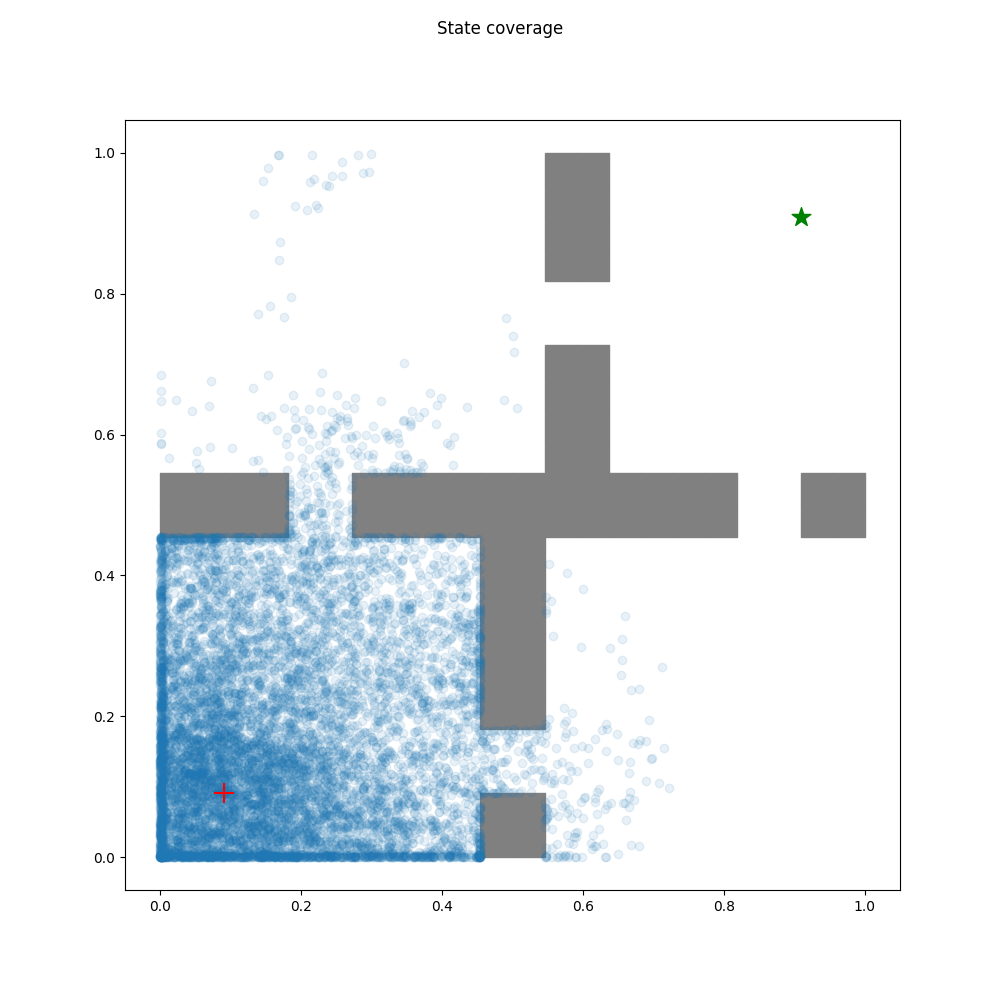
rnd Agent
The Random Network Distillation algorithm encourages exploration by
training another neural network to approximate the output of a randomly
initialized target network, using the discrepancy in predictions to
explore new state-action spaces.
ParseError: KaTeX parse error: Expected group after '^' at position 5: \phi^̲_ = \arg\min*{\…
- Update rnd network
target_features = self.rnd_target_net(obs)
predicted_features = self.rnd_net(obs)
loss = nn.functional.mse_loss(predicted_features, target_features)
- Compute rnd bonus for rewards
rewards = rewards.float() + self.rnd_weight * rnd_error
python cs285/scripts/run_hw5_explore.py \
-cfg experiments/exploration/pointmass_easy_rnd.yaml \
--dataset_dir datasets/ --log_interval 1000
python cs285/scripts/run_hw5_explore.py \
-cfg experiments/exploration/pointmass_medium_rnd.yaml \
--dataset_dir datasets/ --log_interval 1000
python cs285/scripts/run_hw5_explore.py \
-cfg experiments/exploration/pointmass_hard_rnd.yaml \
--dataset_dir datasets/ --log_interval 1000
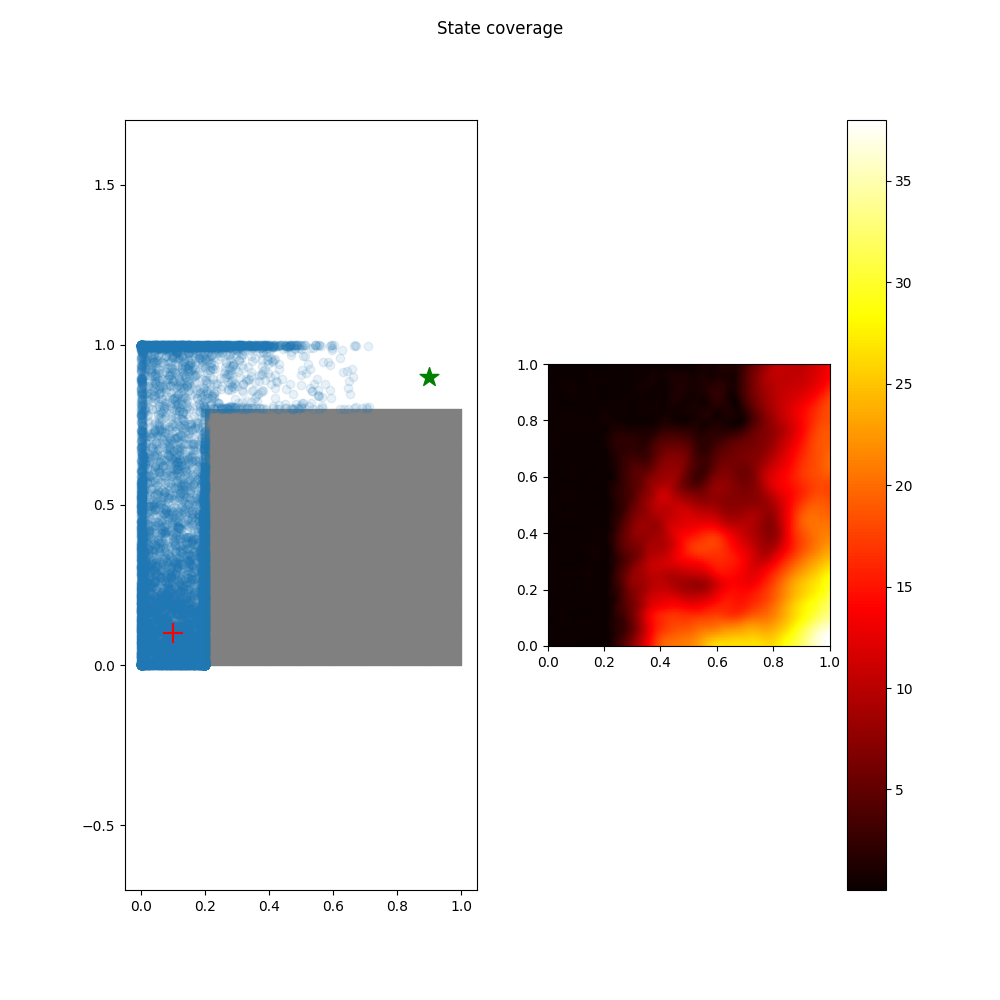
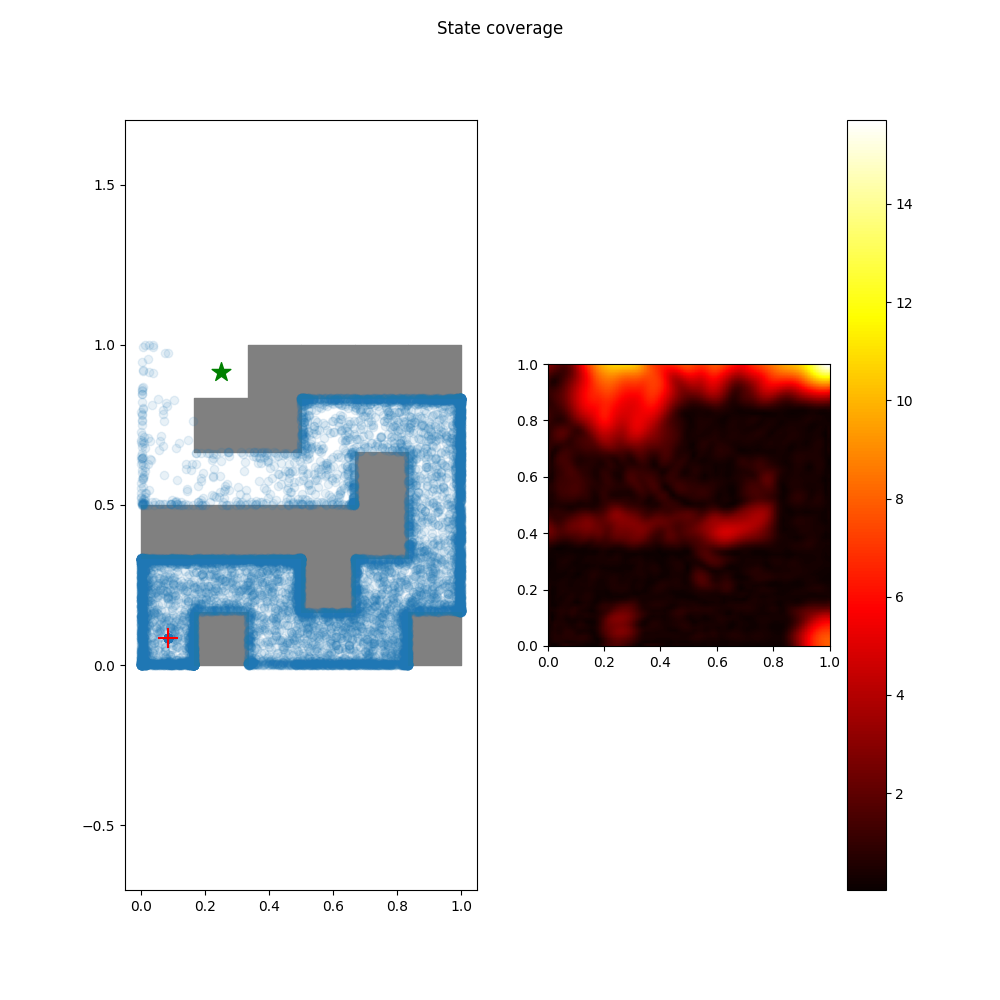
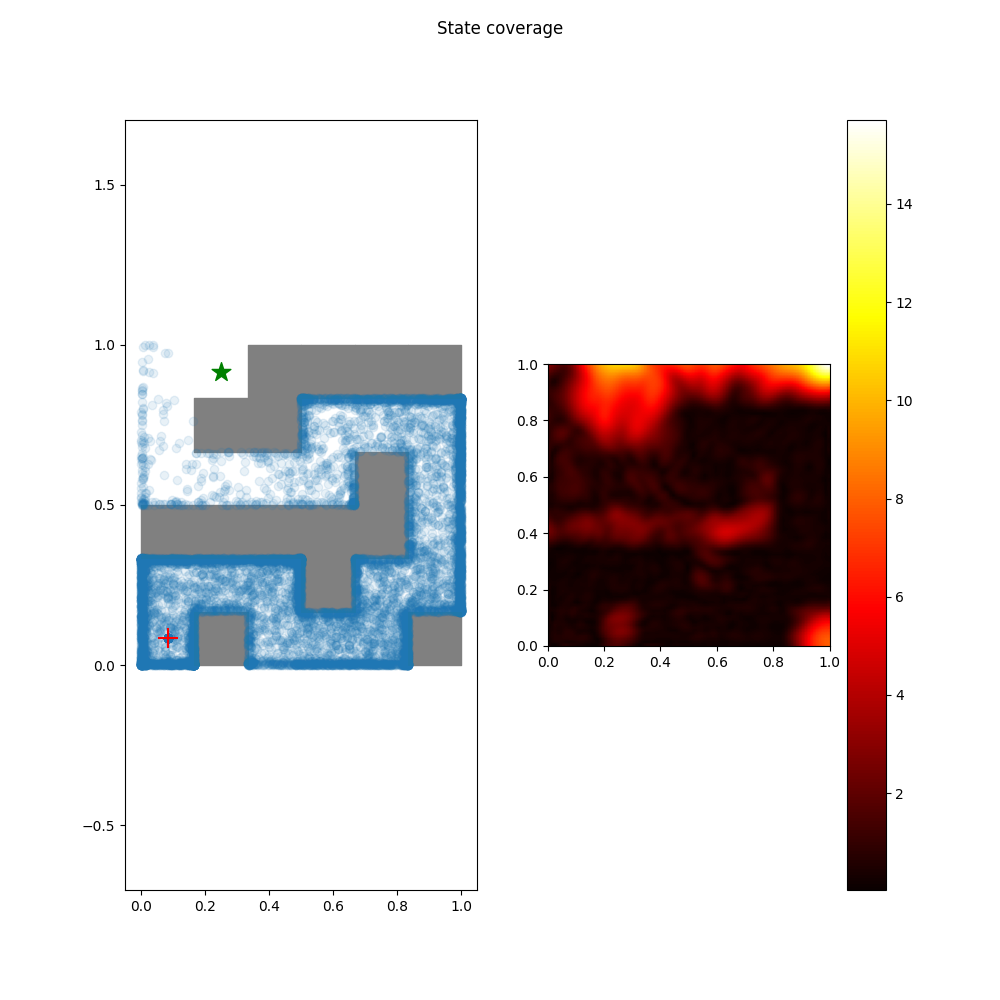
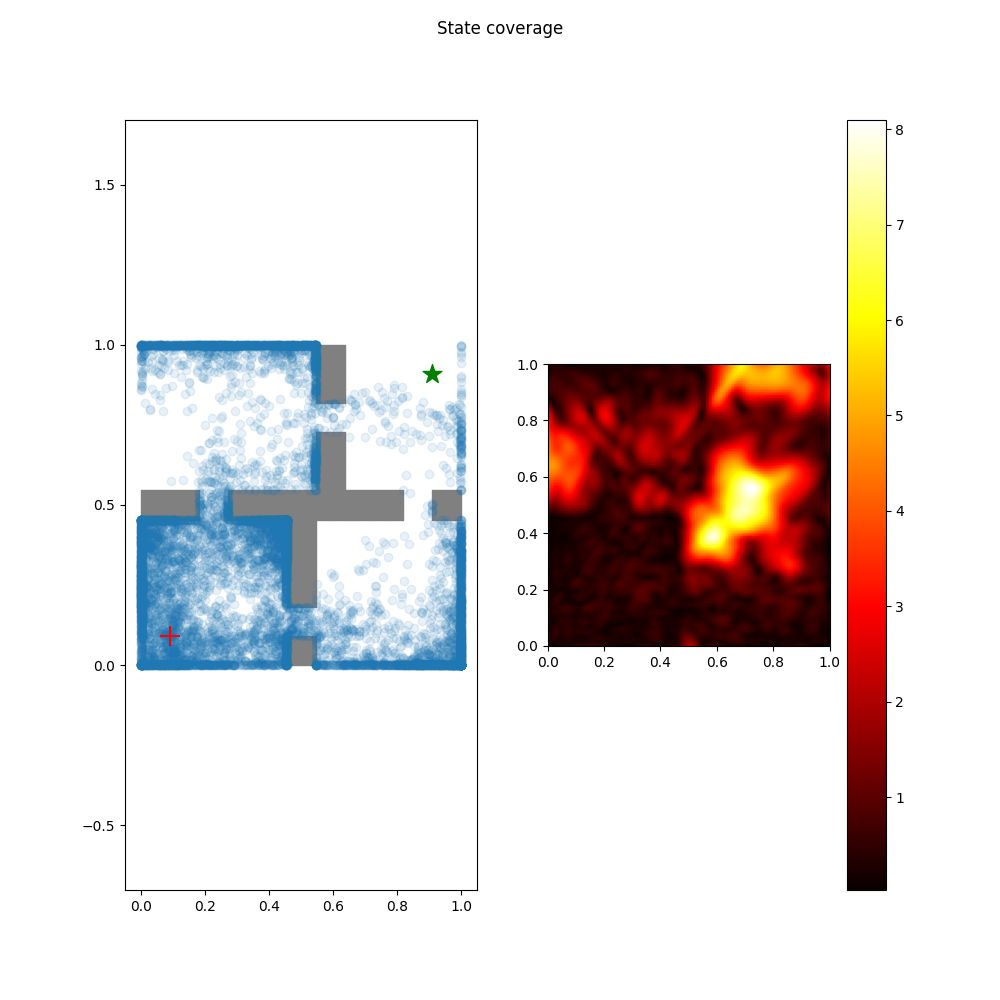
Offline RL
dqn Agent
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_easy_dqn.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_dqn.yaml \
--dataset_dir datasets --log_interval 1000
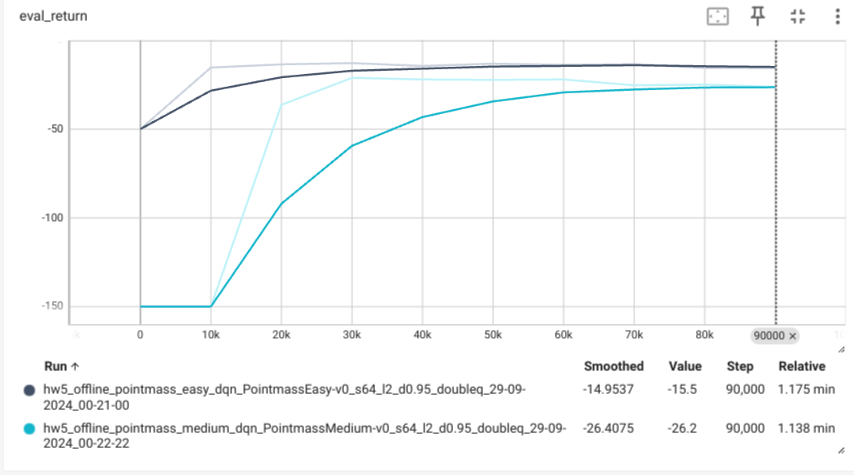
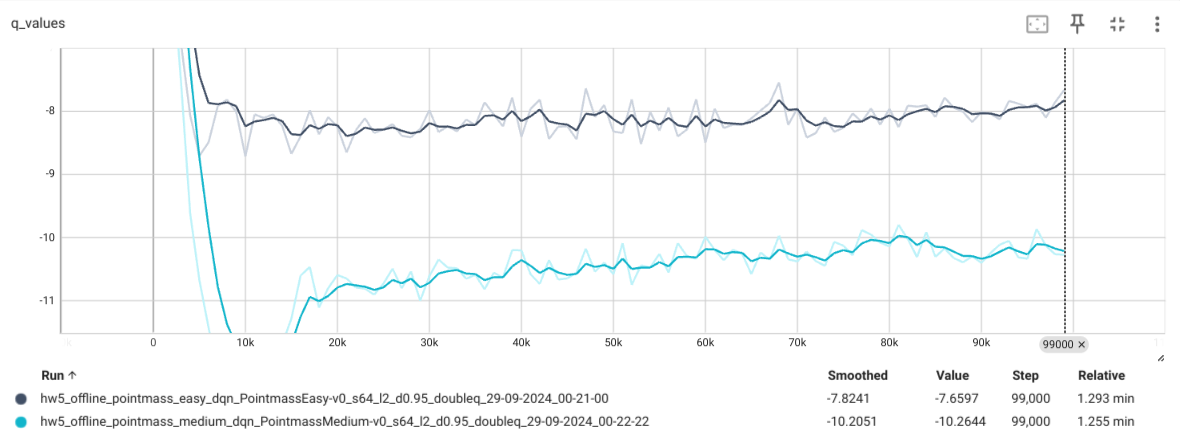
cql Agent
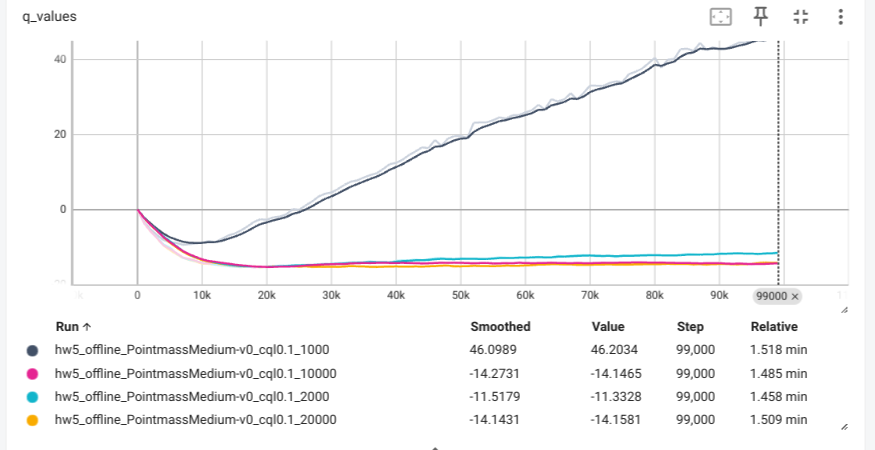
Conservative Q-Learning in offline reinforcement learning aims to prevent policy value overestimation by learning a lower-bound Q-function, reducing those for unseen state-action pairs.
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_easy_cql.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_cql.yaml \
--dataset_dir datasets --log_interval 1000
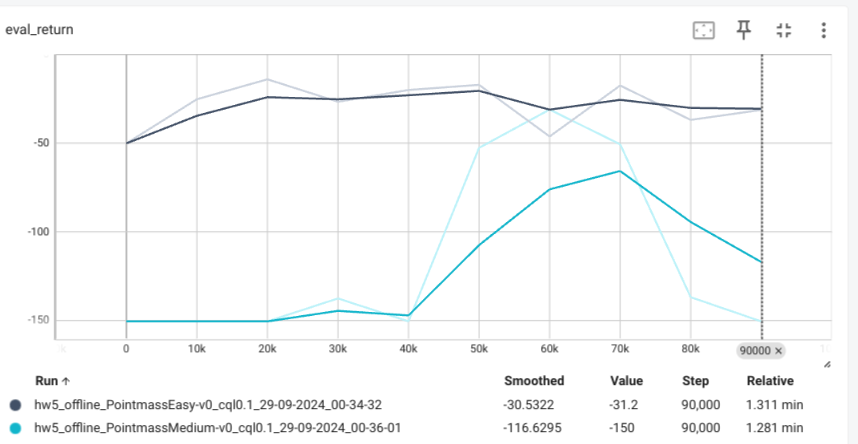
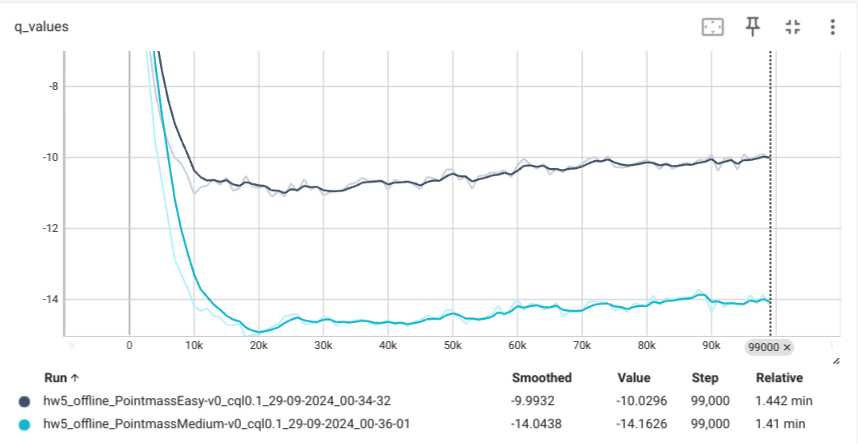
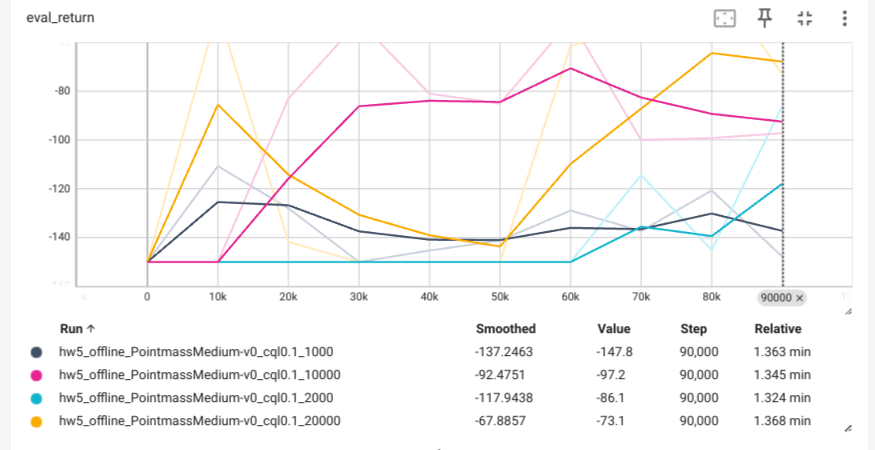
We change cql alpha to different values(default 0.1)
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_cql_alpha0.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_cql_alpha0.1.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_cql_alpha1.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_cql_alpha10.yaml \
--dataset_dir datasets --log_interval 1000
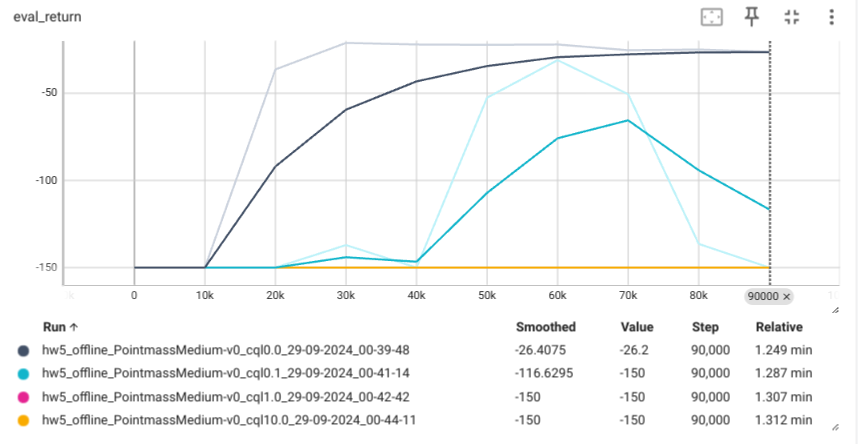
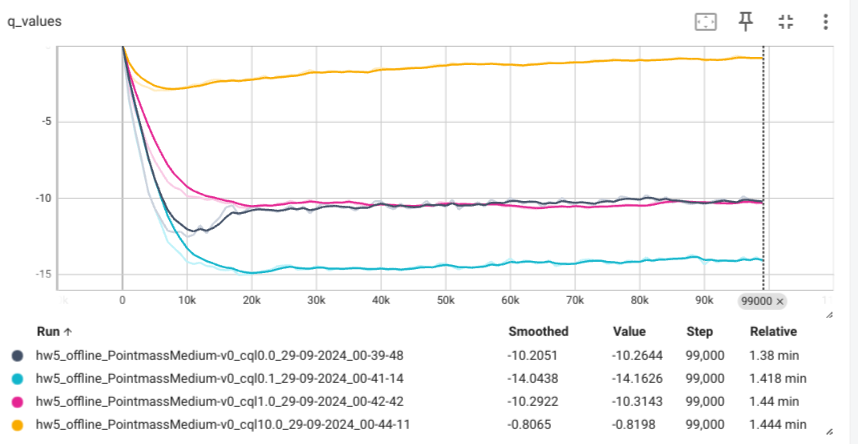
awac Agent
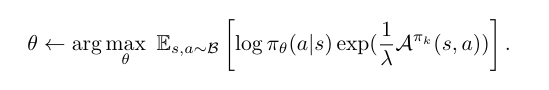
- Compute critic_loss
categorical_dist = self.actor(observations)
logits = categorical_dist.logits
log_probs = torch.log_softmax(logits, dim=-1)
selected_log_probs = log_probs.gather(1, actions.unsqueeze(-1)).squeeze(-1)
advantages = self.compute_advantage(observations, actions)
weights = torch.exp(advantages / self.temperature)
loss = -(weights * selected_log_probs).mean()
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_easy_awac.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_awac.yaml \
--dataset_dir datasets --log_interval 1000
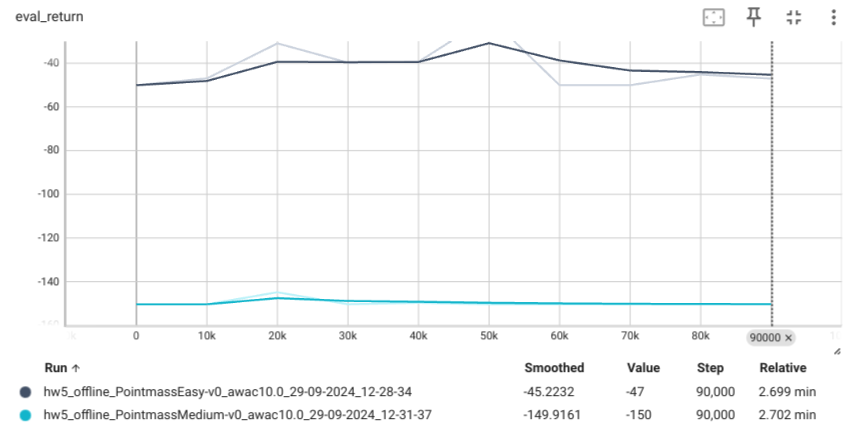
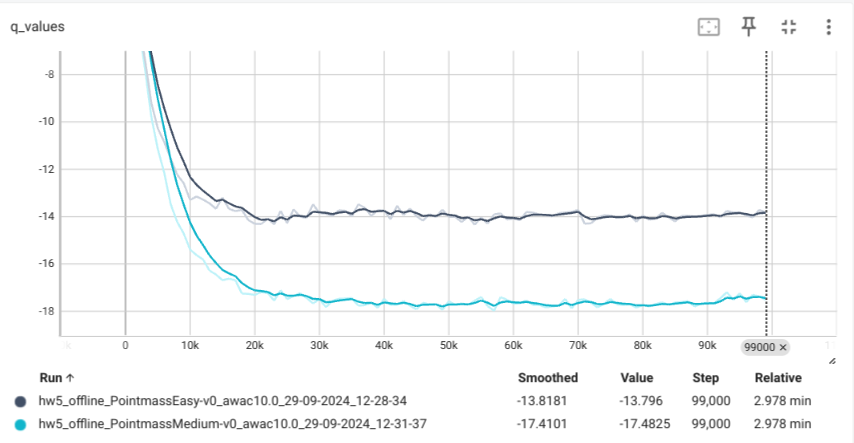
iql Agent
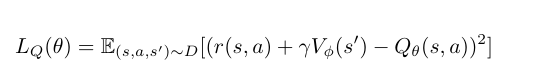
- Expectile loss
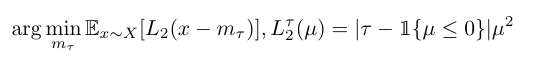
residuals = target_qs - vs
loss = torch.where(residuals < 0, (1 - expectile) * residuals ** 2, expectile * residuals ** 2)
loss = loss.mean()
- Update v
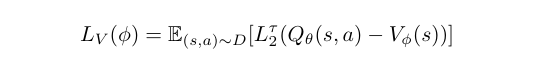
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_easy_iql.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_iql.yaml \
--dataset_dir datasets --log_interval 1000
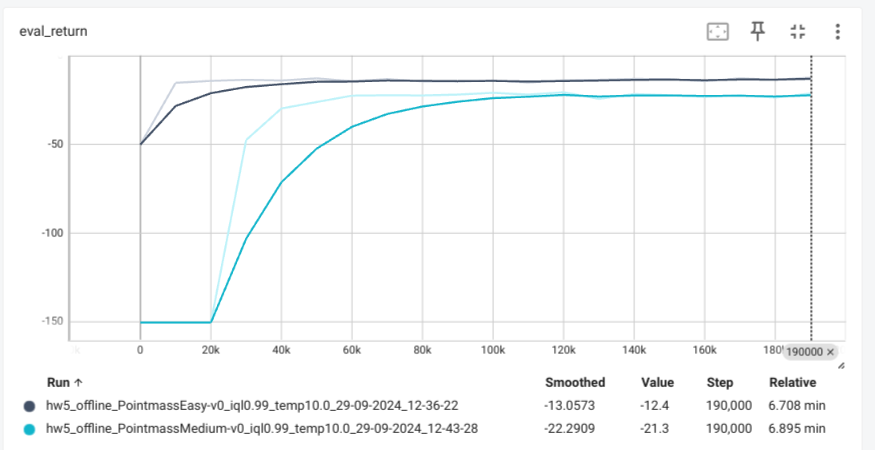
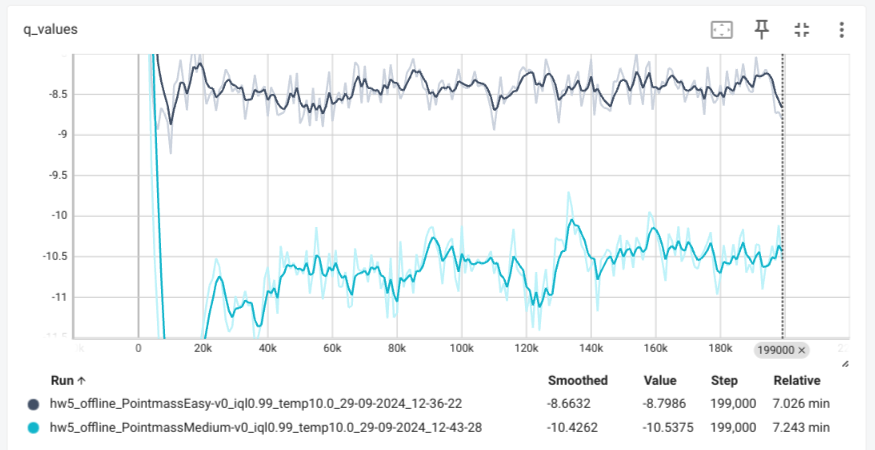
Data ablations for CQL
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_cql_rnd1000.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_cql_rnd5000.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_cql_rnd10000.yaml \
--dataset_dir datasets --log_interval 1000
python ./cs285/scripts/run_hw5_offline.py \
-cfg experiments/offline/pointmass_medium_cql_rnd20000.yaml \
--dataset_dir datasets --log_interval 1000